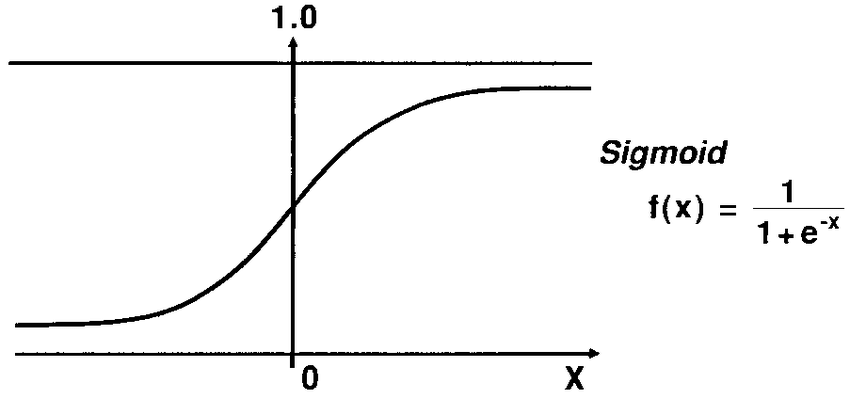
September 06th, 2019
Today’s work
- Self-study for Gaussian Process
- Multivariate Normal Distribution
- Cholesky Decomposition - Generating Multivariate Normal Random Number
- Bayesian Optimization (Fully understanding this is final goal)
Since I am going to tune hyperparameter of GBM like LightGBM or Catboost for the Kaggle Competition that I am now in, I’d like to fully understand how the Bayesian Optimization. While studying these, I have been learning more detail of matrix decomposition and Gaussian Distrubiton. I’ve also been realizing that how important they are in machine learning.
- New Posts
- Schur Complement
- Cholesky Decomposition
A hard one for these posts is that I wasn’t sure how deeply I should study for them. Both of Schur Complement and Cholesky Decomposition are widely and significantly used in statistics.
2019년 9월 6일
오늘 할 일
- Gaussian Process 셀프 스터디
- Multivariate Normal Distribution
- Cholesky Decomposition - Generating Multivariate Normal Random Number
- Bayesian Optimization (Fully understanding this is final goal)
Gaussian Process 를 공부하게 된 계기는 현재 참여하고 있는 Kaggle 대회에서 LightGBM 이나 Catboost 알고리즘을 사용하려 하는데, 여기서 Hyperparameter tuning을 Random Search 나 Grid Search 가 아닌 Bayesian Optimization을 사용하기에 공부하기 시작했다.
공부하다보니 가장 기본이 되는 Matrix Decomposition, Gaussian Distribution등에 대해 더 자세히 배우고 있으며, 이들이 머신러닝에서 얼마나 많이 사용되며 중요한지 배우게 되었다.
- 새로운 포스팅
- Schur Complement
- Cholesky Decomposition
이번 포스팅중 어려웠던 점은 Schur Complement과 Cholesky Decomposition은 Matrix 를 다루는 분석 혹 연구에서 매우 중요하게, 그리고 많이 쓰이기에 그 개념들을 얼마나 깊게 공부해야 하는지였다. 결국 다른 공부를 할때에도 그 개념들은 이어질테니 그때 다시 더 깊게 공부해보고 싶다.