This post will discuss Central Limit Theorem. Central Limit Theorem is one of the most important topic in statistics, especially in probability theory.
$\large{Definition}$:
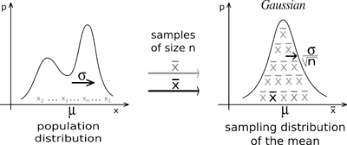
The sample average of independent and identically distributed random variables drawn from an unknown distribution with mean $\mu$ and variance $\sigma$ is approximately normal distributed when $n$ gets larger. That is, by the law of large numbers, the sample mean converges in probability and almost surely to the expected value $\mu$ as $n \to \infty$.
Formally, let ${X_1,X_2,…X_n}$ be random samples of size $n$. Then, the sample average is defined as
$$S_n = \frac{X_1 + X_2 + … + X_n}{n}$$ with mean $\mu$ and variance $\sigma^2$
for(i in 1:length(x1)){ sampled.30[i] <- mean(sample(x1, 30, replace=TRUE)) #sample average of size 30 sampled.1000[i] <- mean(sample(x1, 1000, replace=TRUE)) #sample average of size 1000 sampled.10000[i] <- mean(sample(x1,10000,replace=TRUE)) #sample average of size 10000 }
It shows the $\sqrt{n}(S_n-\mu)$ tends to go to zero as the size of the sample increases, which means that the expected value of the sample average variables gets closer to the expected value of the random variables when $n$ gets larger.
Let’s see other example for random sample average drawn from Binomial distribution.
Suppose we have 10000 random Binomial variables with $p = 0.5$.
1 2 3 4
#Binomial n <- 10000 p <- 1/2 B <- rbinom(n,1,p)
The mean of Binomial distribution is $p$, that is $E(X) = p$. The variance of Binomial distribution is $p(1-p)$, that is $Var(X) = p(1-p)$
1 2 3
p
## [1] 0.5
1 2 3
p*(1-p)
## [1] 0.25
1 2 3
mean(B)
## [1] 0.4991
1 2 3
var(B)
## [1] 0.2500242
1 2 3 4 5 6 7 8 9 10
#creating random sample average from Binomial random variables bin.sampled.30 <- rep(0, length(B)) bin.sampled.1000 <- rep(0,length(B)) bin.sampled.10000 <- rep(0,length(B))
These results shows that no matter what the distribution of the population is, the sample average drawn from the distribution will be approximately normal distribution as $n$ gets large with mean $\mu$.